Performing a parallel pre-trend test in universal absorbing treatments in R
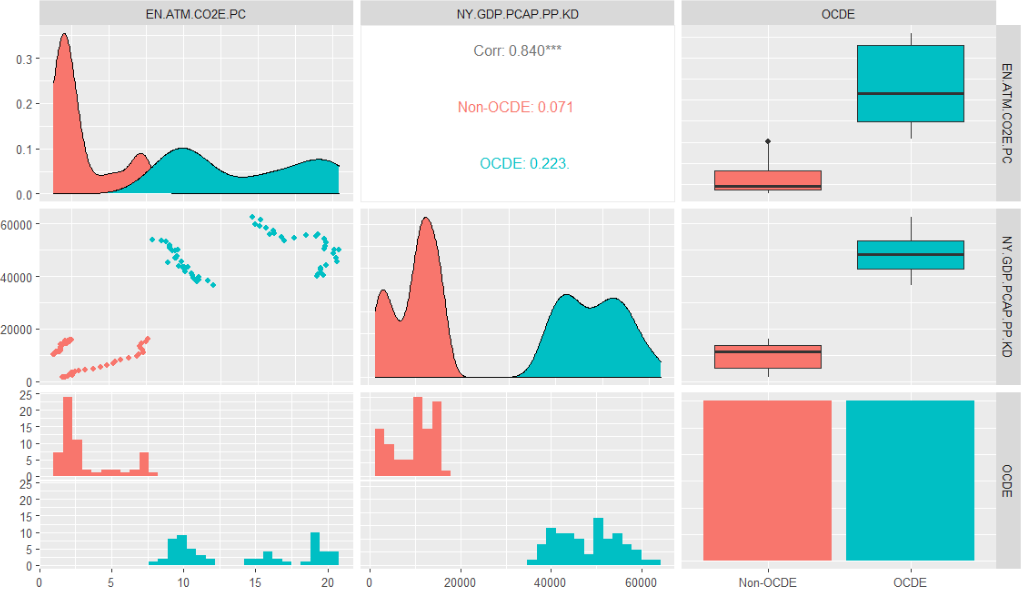
Introduction In a recent paper from the Journal of Research, Innovation and Technologies published last year, there was a significant discussion (Riveros Gavilanes, 2023) about how control variables might be related to the fulfillment of parallel trends in event study (or dynamic differences-in-differences) of panel data. In this article, we will replicate such paper and […]
Performing a parallel pre-trend test in universal absorbing treatments in R Read More »